
This website provides an overview of the software processing of medical data, with an emphasis on the traps that are often present.
|
|
Healthcare Data QA
This website provides an overview of the software processing of medical data, with an emphasis on the traps that are often present. |
| Home Introduction Software Design Basic Obstacles Data Input Problems Human Obstacles EHR DataBases CSV Files XML Files Reports Statistics Legal Other © 2022 Kevin Pardo | XMLXML/HTML is fine for free-form web pages, but it does poorly when data is to be loaded into a relational database. XML Maps Poorly into Relational Databases: Most bulk data is stored in relational databases. The table structure of a relational database makes a rigid and limited environment for data storage. When young, we don't appreciate this. We see XML, with its permitted variations, as offering more freedom than relational databases. In reality, XML does not encourage the clean organization of data. Also, the major XML file formats for medical data are outright bizarre.Most of us had positive initial impressions of XML, but in real life it often grates horribly with the table structure of relational databases. Eventually we find that relational databases and CSV files are a much better fit than data exchanges with XML. Lunatic Section and Value Tags: Many files are sophisticated enough to be used by the UN's World Health Organization to analyze population data. However, the level of sophistication in XML healthcare files is excessive for healthcare within the US. XML healthcare files are, in practice, extremely cryptic. Much of the structure of XML files is literally unreadable without dictionaries for meaningless tags. Here are some of the
CMS QRDA III implementation details. These are to be followed by people submitting data to CMS,
not simply used internally.
A sane and helpful section tag for the initial population (IPOP) for
CMS measure 2 version 11 would be: CMS2_V11_IPOP
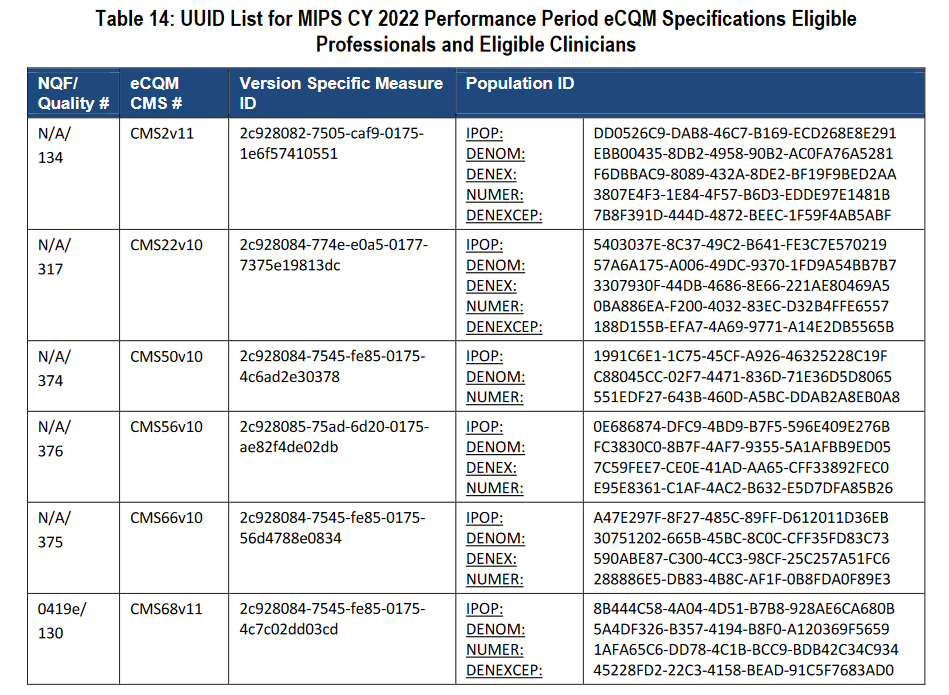 Note that this is only the top of the table for 2022. There are several pages of these section tags. There is also an international set of OID codes for field/value definitions. Variability in Batch Dumps: You would expect a data provider for five clinics using the same EHR to give you XML files with the equivalent content for all five clinics. Whether out of incompetence or malice, you may find that such files vary dramatically in content. How far each file goes back in time may be different, for example. If you miss this, you may be reading files in which some patient data is detailed for years while other files contain only recent data, or data for a single encounter. Don't tolerate any excuses from the data suppliers. For five clinics, demand that they configure the generation to be the same for all five clinics, and that the content should be as close a match to your project as possible. Variability in Fields: After processing thousands of files, someone may notice that harvesting has dropped some values. You may find the cause to be variation where none is expected or justified. Corrupt Files: Some XML export functionality has only been added for marketing or government compliance. One EHR's XML files were literally too corrupt to be read by standard XML input libraries. Difficult to Search: If a patient with MRN 123456 may be missing A1C lab data because of a harvesting error, it is trivial to search CSV files in bulk using standard tools. (Some variability in CSV files may cause annoyances, but manual searches are still practical.) With XML, you waste more time and effort than would be required with CSV files.  |